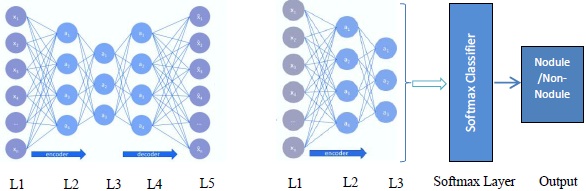
Fig. (4)
Proposed deep autoencoder model.